V-PRISM: Probabilistic Mapping of Unknown Tabletop Scenes
Herbert Wright1, Weiming Zhi2, Matthew Johnson-Roberson2, Tucker Hermans1,3

Abstract
The ability to construct concise scene representations from sensor input is central to the field of robotics. This paper addresses the problem of robustly creating a 3D representation of a tabletop scene from a segmented RGB-D image. These representations are then critical for a range of downstream manipulation tasks. Many previous attempts to tackle this problem do not capture accurate uncertainty, which is required to subsequently produce safe motion plans. In this paper, we cast the representation of 3D tabletop scenes as a multi-class classification problem. To tackle this, we introduce V-PRISM, a framework and method for robustly creating probabilistic 3D segmentation maps of tabletop scenes. Our maps contain both occupancy estimates, segmentation information, and principled uncertainty measures. We evaluate the robustness of our method in (1) procedurally generated scenes using open-source object datasets, and (2) real-world tabletop data collected from a depth camera. Our experiments show that our approach outperforms alternative continuous reconstruction approaches that do not explicitly reason about objects in a multi-class formulation.
Overview of our Method
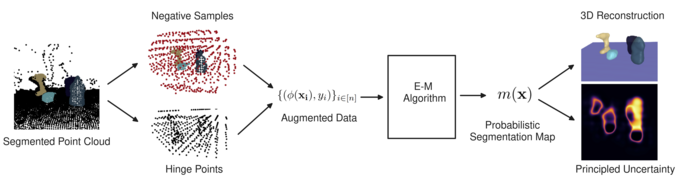
We take a segmented point cloud, generate negative samples and hingepoints in order to construct an augmented set of data. Then, we run an EM algorithm to produce a probabilistic map. This map can be used to reconstruct the objects or measure uncertainty.
V-PRISM Captures Principled Uncertainty
We compare our method to a non-Bayesian version trained with gradient descent instead of our proposed EM Algorithm. Top row: the observed point cloud with a green plane corresponding to the 2D slice where the heat maps were calculated. We compare a non-probabilistic variant of V-PRISM trained with gradient descent (middle row) and our method (bottom row). In the heat maps, the bottom is closer to the camera and the top is farther from the camera. Lighter areas correspond to more uncertainty. Our method predicts high uncertainty in occluded areas of the scene.

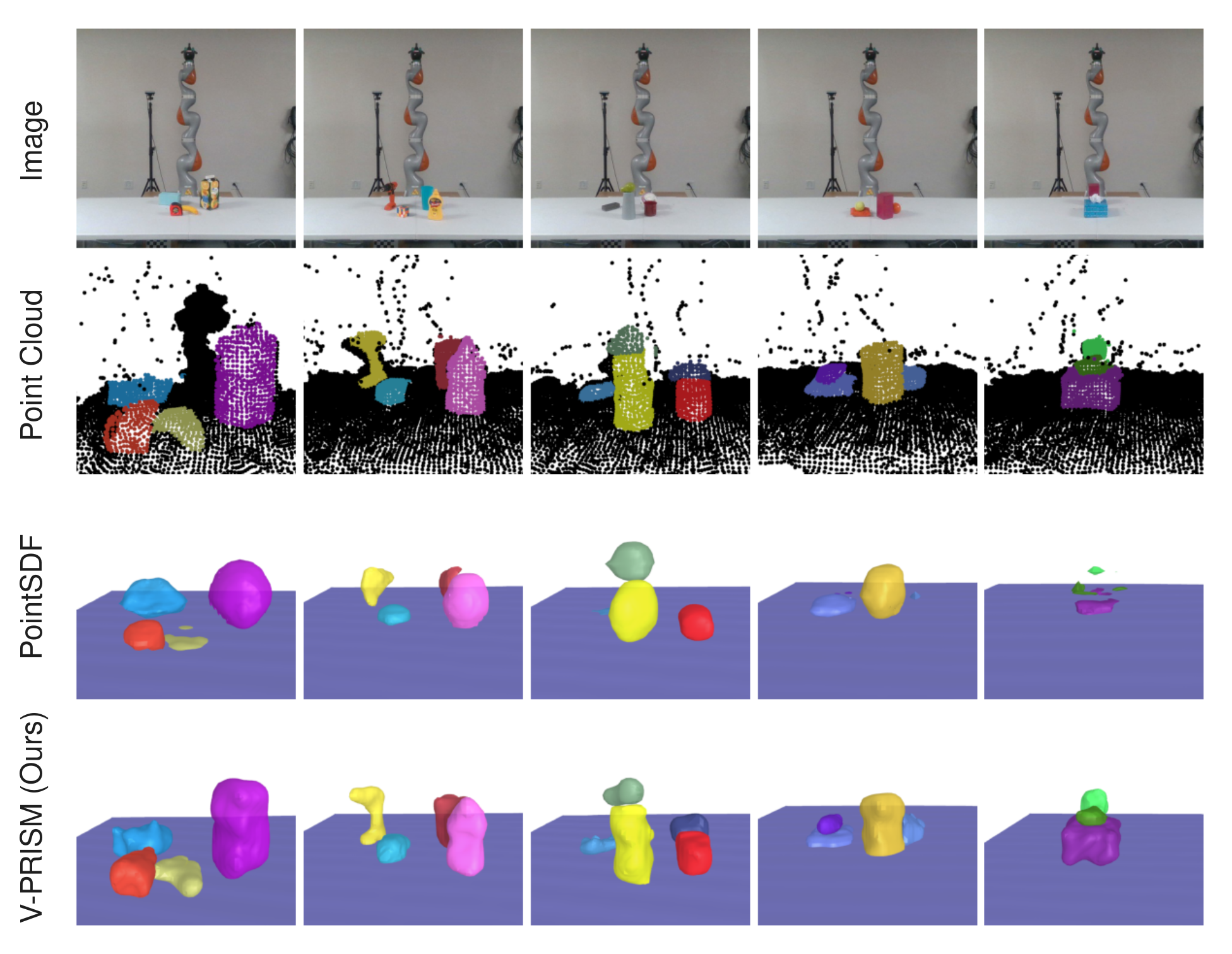
V-PRISM Can Reconstruct Real-World, Noisy Scenes
We compare against a PointSDF architecture trained on ShapeNet scenes on real world, noisy scenes. First row: RGB images. Second row: the segmented point cloud used as input. Third row: PointSDF reconstructions. Last row: V-PRISM's (our method) reconstructions. Our method results in quality reconstructions on noisy scenes where PointSDF struggles.